Splunk 是一套的 Log 监控软体,它可以分析任何格式的 Log 资料,透过 Splunk ,我们可以分析页面或 API的使用率,找到未知的 Bug ,自订搜寻条件快速找到各种资料,并产出报表与画出各式各瓶的图表,最棒的是,当系统有问题的时候可以自动透过 Email 即时通知维护人员。
这套软体有提供免费的版本,免费版上限是一天最多只能有 500MB , 对於一版普通的网站来说是够了,像我自已的部落格根本就用不完!!
如何快速安装 Splunk
我是使用 Docker compose 来安装 Splunk,使用 Docker 十分钟内就可以安装完成,可以说是非常的轻松, docker-compose.yml 设定如下,SPLUNL_PASSWORD 跟 SPLUNK_START_ARGS 是必填,管理员帐号预设是 admin ,密码就是 SPLUNL_PASSWORD 这个环境变数填的值。
- version: '3'
- services:
- splunk:
- image: splunk/splunk:latest
- container_name: splunk
- environment:
- - SPLUNK_START_ARGS=--accept-license
- - SPLUNK_PASSWORD=yourpassword
- ports:
- - 8000:8000
- volumes:
- - /var/logs:/var/logs
装好后启动 splunk: docker-compose up,再登入 http://localhost:8000/ 就会出现登入页面,输入 admin 跟 password 后就可以开始使用。
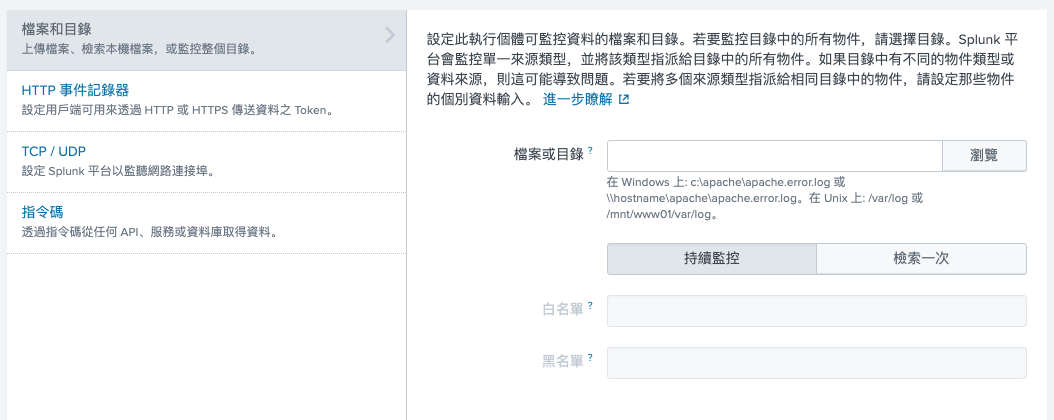
设定 local log file
登入 Splunk 后,第一个步骤是要新增 log file ,这里我是使用 local log file ,先选右上角 settings (设定) Data inputs (资料输入) ,点击 Files & Directories右边的 add new 按钮,你就会看到下图这个页面,在档案的地方输入 local 档案路径即可,如 "/var/log/apache.log" 。
搜寻关键字
在输入 log file 之后,你就可以进入 Splunk Search UI 开始搜寻 Log, 它使用的搜寻语法是 Splunk 公司自订的 SPL (search processing language),SPL 语法可读性还不错,可以说是一种易读易写的语法,也支援 Regular Expression,Splunk SPL 语法简介: https://www.puritys.me/docs-blog/article-415-Splunk-%E8%AA%9E%E6%B3%95.html , 如果你第一次使用不知道要搜寻什么,使用万用字元 * 就对了,另外SPL 也支援 linux system pipe 的语法,透过 | pipe 把上一个 Command 拿到的结果丢给下个 Command 处理。
- source="/var/logs/ats/squid.log"
- | rex field=_raw "[0-9\.]+ (?<duration_ms>[0-9]+) (?<remote_ip>[0-9\.]+) (?<status>[^\s]+) (?<size>[0-9]+) (?<method>[A-Z]+) (?<url>[^\s]+)"
- | table _time,remote_ip,status,duration_ms,method,url,size,_raw
建立警示 (Alert)
警示是 Splunk 很重要的一项功能,我们可以透过警示让 Splunk 即时通知线上系统的情况,例如我想要当系统出现大量 errors 时 (http status = 500) ,能够立即通知维护人员。
- source="/var/logs/access.log"
- | rex "\"(GET|POST|PUT|DELETE) (?<url>[^\"]+) (?<http>[^\s]+)\" (?<status>[0-9]+)"
- | search status=500
- | stats count
有一个 error 就送通知的话,可能会太困扰人,你可以设定当 10 分钟内 error 数超过 100 再寄通知。
避免 Splunk Alert 变成放羊的小孩
某些情况下系统会因网路问题,或是系统不明原因重启(oom process auto restart),使得某个服务突然停止运作,而造成其它服务产生大量的 500 error ,但是过了几秒后网路恢复正常了,或是系统已重启完成, Error 数又降下来,若每天发生个几次,久而久之 Alert 就会变成放羊的小孩,没有人再想要去理它,这种问题在超大型系统架构下还蛮常会发生的,你只能顾好自已开发的服务,没办法要求其它工程师把他们的服务也弄稳定,通常我会用 Splunk 来抓出持续性的不稳定,而忽略突发且短暂的不稳定,作法是每 2 分钟计算一次 Error 数,如果连续出现 5 次 Errors 数过多,代表问题已持续发生 10 分钟,这时再寄通知,这个方法可以大大的减少这种无解的 Alert (自已没有权限 or 时间去解别人的问题)。
语法是这样写的,另外在 Splunk alert UI 填上当 count 数大於 4 才寄通知 ( 有超过 4 次 Error 数大於 1000 )。
- | bucket _time span=2m | count by _time | search count > 1000