Splunk 是一套的 Log 監控軟體,它可以分析任何格式的 Log 資料,透過 Splunk ,我們可以分析頁面或 API的使用率,找到未知的 Bug ,自訂搜尋條件快速找到各種資料,並產出報表與畫出各式各瓶的圖表,最棒的是,當系統有問題的時候可以自動透過 Email 即時通知維護人員。
這套軟體有提供免費的版本,免費版上限是一天最多只能有 500MB , 對於一版普通的網站來說是夠了,像我自已的部落格根本就用不完!!
如何快速安裝 Splunk
我是使用 Docker compose 來安裝 Splunk,使用 Docker 十分鐘內就可以安裝完成,可以說是非常的輕鬆, docker-compose.yml 設定如下,SPLUNL_PASSWORD 跟 SPLUNK_START_ARGS 是必填,管理員帳號預設是 admin ,密碼就是 SPLUNL_PASSWORD 這個環境變數填的值。
- version: '3'
- services:
- splunk:
- image: splunk/splunk:latest
- container_name: splunk
- environment:
- - SPLUNK_START_ARGS=--accept-license
- - SPLUNK_PASSWORD=yourpassword
- ports:
- - 8000:8000
- volumes:
- - /var/logs:/var/logs
裝好後啟動 splunk: docker-compose up,再登入 http://localhost:8000/ 就會出現登入頁面,輸入 admin 跟 password 後就可以開始使用。
設定 local log file
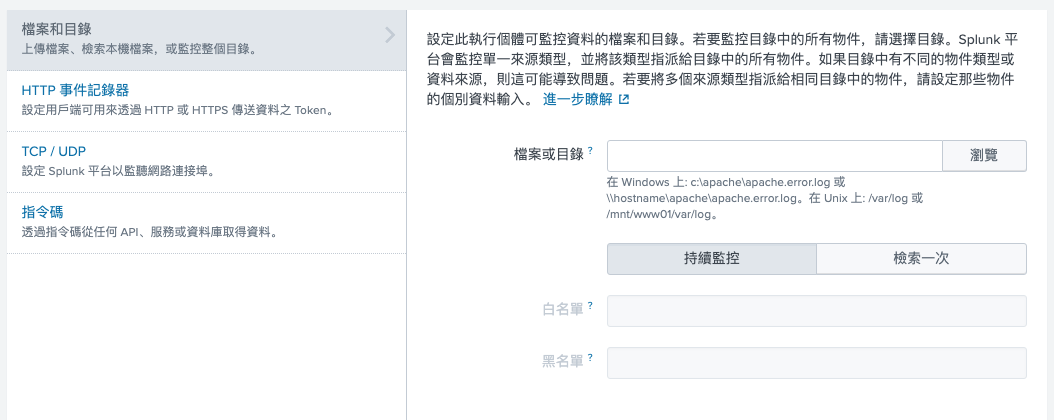
登入 Splunk 後,第一個步驟是要新增 log file ,這裡我是使用 local log file ,先選右上角 settings (設定) Data inputs (資料輸入) ,點擊 Files & Directories右邊的 add new 按鈕,你就會看到下圖這個頁面,在檔案的地方輸入 local 檔案路徑即可,如 "/var/log/apache.log" 。
搜尋關鍵字
在輸入 log file 之後,你就可以進入 Splunk Search UI 開始搜尋 Log, 它使用的搜尋語法是 Splunk 公司自訂的 SPL (search processing language),SPL 語法可讀性還不錯,可以說是一種易讀易寫的語法,也支援 Regular Expression,Splunk SPL 語法簡介: https://www.puritys.me/docs-blog/article-415-Splunk-%E8%AA%9E%E6%B3%95.html , 如果你第一次使用不知道要搜尋什麼,使用萬用字元 * 就對了,另外SPL 也支援 linux system pipe 的語法,透過 | pipe 把上一個 Command 拿到的結果丟給下個 Command 處理。
- source="/var/logs/ats/squid.log"
- | rex field=_raw "[0-9\.]+ (?<duration_ms>[0-9]+) (?<remote_ip>[0-9\.]+) (?<status>[^\s]+) (?<size>[0-9]+) (?<method>[A-Z]+) (?<url>[^\s]+)"
- | table _time,remote_ip,status,duration_ms,method,url,size,_raw
建立警示 (Alert)
警示是 Splunk 很重要的一項功能,我們可以透過警示讓 Splunk 即時通知線上系統的情況,例如我想要當系統出現大量 errors 時 (http status = 500) ,能夠立即通知維護人員。
- source="/var/logs/access.log"
- | rex "\"(GET|POST|PUT|DELETE) (?<url>[^\"]+) (?<http>[^\s]+)\" (?<status>[0-9]+)"
- | search status=500
- | stats count
有一個 error 就送通知的話,可能會太困擾人,你可以設定當 10 分鐘內 error 數超過 100 再寄通知。
避免 Splunk Alert 變成放羊的小孩
某些情況下系統會因網路問題,或是系統不明原因重啟(oom process auto restart),使得某個服務突然停止運作,而造成其它服務產生大量的 500 error ,但是過了幾秒後網路恢復正常了,或是系統已重啟完成, Error 數又降下來,若每天發生個幾次,久而久之 Alert 就會變成放羊的小孩,沒有人再想要去理它,這種問題在超大型系統架構下還蠻常會發生的,你只能顧好自已開發的服務,沒辦法要求其它工程師把他們的服務也弄穩定,通常我會用 Splunk 來抓出持續性的不穩定,而忽略突發且短暫的不穩定,作法是每 2 分鐘計算一次 Error 數,如果連續出現 5 次 Errors 數過多,代表問題已持續發生 10 分鐘,這時再寄通知,這個方法可以大大的減少這種無解的 Alert (自已沒有權限 or 時間去解別人的問題)。
語法是這樣寫的,另外在 Splunk alert UI 填上當 count 數大於 4 才寄通知 ( 有超過 4 次 Error 數大於 1000 )。
- | bucket _time span=2m | count by _time | search count > 1000